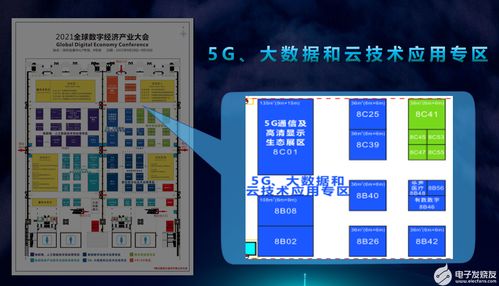
在2018年的WMT(Workshop on Machine Translation)機器翻譯大賽中,阿里達摩院憑借其創(chuàng)新的大規(guī)模集成Transformer模型,一舉奪魁,展現(xiàn)了在信息系統(tǒng)集成服務(wù)領(lǐng)域的卓越能力。這一成就不僅推動了機器翻譯技術(shù)的進步,也為企業(yè)級信息系統(tǒng)解決方案提供了寶貴經(jīng)驗。在本次專訪中,我們將深入探討達摩院團隊如何構(gòu)建這一獲獎系統(tǒng),并分析其背后的技術(shù)策略與集成服務(wù)實踐。
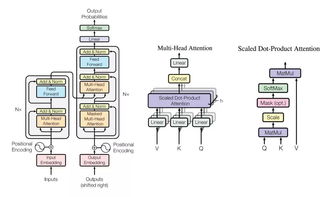
達摩院團隊聚焦于Transformer模型的規(guī)模化集成。Transformer作為一種基于自注意力機制的神經(jīng)網(wǎng)絡(luò)架構(gòu),自提出以來便在自然語言處理任務(wù)中表現(xiàn)優(yōu)異。單模型性能往往受限于數(shù)據(jù)多樣性和模型復(fù)雜度。為此,團隊采用了大規(guī)模集成方法,通過訓(xùn)練多個Transformer模型變體,并結(jié)合投票或加權(quán)平均機制進行結(jié)果融合。這種方法有效提升了翻譯的準確性和魯棒性,尤其在處理多語言、長句和領(lǐng)域特定文本時表現(xiàn)突出。例如,在WMT 2018的英德翻譯任務(wù)中,集成的模型在BLEU分數(shù)上顯著超越了單模型基準。
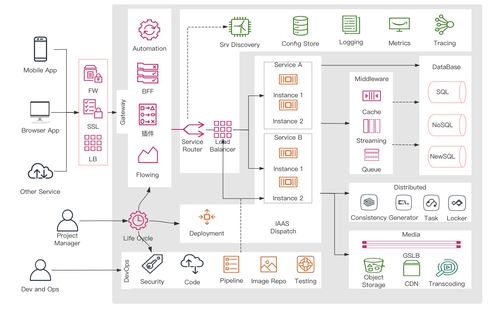
信息系統(tǒng)集成服務(wù)在這一過程中扮演了關(guān)鍵角色。阿里達摩院充分利用了其強大的云計算和分布式計算基礎(chǔ)設(shè)施,實現(xiàn)了高效的數(shù)據(jù)處理、模型訓(xùn)練和推理部署。團隊采用了模塊化設(shè)計,將數(shù)據(jù)預(yù)處理、模型訓(xùn)練、評估和部署等環(huán)節(jié)無縫集成,確保了系統(tǒng)的可擴展性和可靠性。通過集成多源數(shù)據(jù)和服務(wù),如多語言語料庫和實時翻譯API,系統(tǒng)能夠適應(yīng)多樣化的用戶需求,提供高質(zhì)量的機器翻譯服務(wù)。這種集成方法不僅優(yōu)化了性能,還降低了運營成本,體現(xiàn)了信息系統(tǒng)集成服務(wù)在企業(yè)應(yīng)用中的核心價值。
在技術(shù)實現(xiàn)上,達摩院團隊強調(diào)了數(shù)據(jù)增強和超參數(shù)調(diào)優(yōu)的重要性。他們通過引入噪聲注入、回譯等技術(shù)擴充訓(xùn)練數(shù)據(jù),增強了模型的泛化能力。利用自動化工具進行超參數(shù)搜索,確保了每個集成模型的最優(yōu)配置。團隊還分享了在模型部署階段的挑戰(zhàn),例如如何處理高并發(fā)請求和確保低延遲響應(yīng)。通過集成容器化技術(shù)(如Docker)和負載均衡策略,系統(tǒng)在WMT評測中展現(xiàn)了出色的穩(wěn)定性和效率。
值得一提的是,這一獲獎系統(tǒng)不僅僅是技術(shù)創(chuàng)新的成果,還體現(xiàn)了阿里達摩院在產(chǎn)學(xué)研結(jié)合上的優(yōu)勢。團隊與學(xué)術(shù)界合作,借鑒了最新的研究成果,并將其快速轉(zhuǎn)化為實際應(yīng)用。這種協(xié)同創(chuàng)新模式,加上強大的信息系統(tǒng)集成能力,使得達摩院能夠在競爭激烈的WMT大賽中脫穎而出。
達摩院計劃進一步擴展集成模型的應(yīng)用范圍,例如結(jié)合多模態(tài)數(shù)據(jù)和強化學(xué)習(xí),以提升機器翻譯在復(fù)雜場景下的表現(xiàn)。他們將持續(xù)優(yōu)化信息系統(tǒng)集成服務(wù),推動技術(shù)在更多行業(yè)落地,如電子商務(wù)、教育和醫(yī)療等領(lǐng)域。
阿里達摩院通過大規(guī)模集成Transformer模型和高效的信息系統(tǒng)集成服務(wù),成功打造了WMT 2018機器翻譯獲勝系統(tǒng)。這一案例不僅展示了技術(shù)在突破語言障礙中的潛力,也為全球企業(yè)提供了可復(fù)用的集成解決方案。我們期待看到更多創(chuàng)新從達摩院誕生,推動人工智能與信息服務(wù)的深度融合。